Wie lässt sich die Datenqualität in KI-Projekten verbessern?
Datenqualität in KI-Projekten
- 09.04.2024
Sicherung der Datenqualität: die größten Herausforderungen
Die Sicherung der Datenqualität ist entscheidend für den Erfolg von KI-Produkten. Zahlreiche Herausforderungen beeinträchtigen jedoch die Qualität und Zuverlässigkeit von Daten in der Praxis, was sich wiederum auf die Leistung und Effizienz von KI-Systemen auswirkt. Ein wesentliches Hindernis sind interne Datensilos. Abteilungsgrenzen und mangelnde Integration isolieren Daten und erschweren ihre Analyse und Nutzung, was wiederum die Entwicklung und das Training von KI-Modellen behindert.Ebenso problematisch sind veraltete IT-Infrastrukturen. Sie behindern die Datenverarbeitung und führen zu Fehlern. Die zunehmende Datenmenge und -vielfalt verschärft diese Probleme.
Mangelndes Vertrauen in die eigenen Daten reduziert die Investitionsbereitschaft in KI. Zweifel an der Richtigkeit und Aktualität der Daten erzeugen Unsicherheiten bei KI-gestützten Entscheidungen.
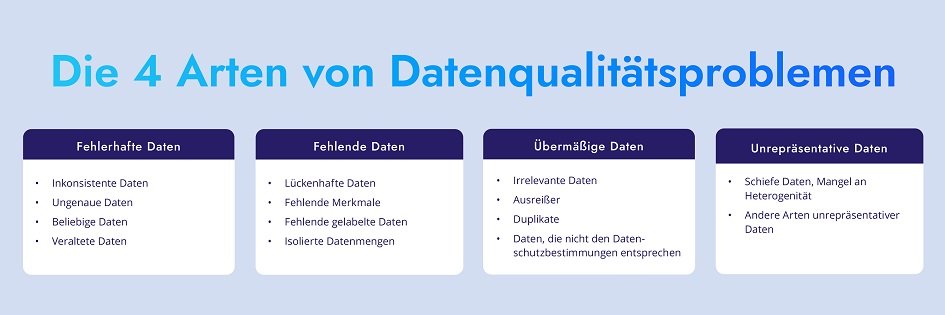
Vier Haupttypen von Datenqualitätsproblemen
Datenqualitätsprobleme lassen sich grob in vier Hauptkategorien einteilen:Die Überwindung dieser Herausforderungen erfordert einen systematischen Ansatz, der sowohl technologische Lösungen als auch organisatorische Veränderungen umfasst, um die Datenqualität in KI-Projekten zu sichern und zu verbessern.
Strategien zur Verbesserung der Datenqualität

Etablierung eines Data Governance Framework
Ein solides Data Governance Framework legt Richtlinien, Verantwortlichkeiten und Prozesse fest, um die Integrität, Sicherheit und Qualität der Daten über ihren gesamten Lebenszyklus hinweg zu gewährleisten. Ein solches Framework fördert Transparenz, erleichtert die Einhaltung von Datenschutzvorschriften und stellt sicher, dass Daten konsistent und vertrauenswürdig sind.
Implementierung fortschrittlicher Datenbereinigungstechniken
Datenbereinigung ist ein kritischer Prozess, um Ungenauigkeiten, Duplikate und Inkonsistenzen in den Daten zu identifizieren und zu korrigieren. Fortschrittliche Techniken wie maschinelles Lernen können eingesetzt werden, um Muster in den Daten zu erkennen und Fehler automatisch zu beheben, was die Effizienz und Genauigkeit der Datenbereinigung erhöht.
Einsatz von Datenintegrationslösungen
Datenintegration ist entscheidend, um Datensilos aufzubrechen und eine einheitliche Sicht auf die Datenbestände zu schaffen. Moderne Datenintegrationslösungen ermöglichen die nahtlose Aggregation, Transformation und Konsolidierung von Daten aus verschiedenen Quellen, wodurch eine kohärente und umfassende Datenbasis für KI-Anwendungen entsteht.
Förderung der Datenkultur im Unternehmen
Eine starke Datenkultur fördert das Bewusstsein und Verständnis für die Bedeutung von Datenqualität auf allen Ebenen des Unternehmens. Schulungen und Workshops können Mitarbeiter befähigen, datengesteuerte Entscheidungen zu treffen und die Prinzipien guter Datenpraktiken in ihren Arbeitsalltag zu integrieren.
Anreicherung von Daten durch externe Quellen
Die Anreicherung von internen Daten mit relevanten externen Informationen kann die Qualität und den Informationsgehalt der vorhandenen Datenbestände erheblich verbessern. Dies kann die Relevanz und Genauigkeit von KI-Modellen steigern, indem zusätzliche Kontextinformationen und Perspektiven einbezogen werden.
Implementierung kontinuierlicher Qualitätskontrollen
Regelmäßige Überprüfungen und Audits der Datenqualität helfen, Probleme frühzeitig zu identifizieren und zu beheben. Kontinuierliche Monitoring-Systeme können automatisch Qualitätsmetriken überwachen und Alarme auslösen, wenn Datenqualitätsstandards nicht eingehalten werden.
Nutzung von KI und maschinellem Lernen zur Qualitätsverbesserung
KI und maschinelles Lernen können nicht nur von hochwertigen Daten profitieren, sondern auch aktiv zur Verbesserung der Datenqualität beitragen. Algorithmen können beispielsweise zur Vorhersage fehlender Werte, zur Identifizierung und Korrektur von Anomalien oder zur Optimierung der Datenklassifizierung eingesetzt werden.
Die Implementierung effektiver Strategien zur Datenqualitätsverbesserung kann die Leistungsfähigkeit und Verlässlichkeit von KI-Initiativen in Unternehmen maßgeblich steigern. Angesichts der Bedeutung kontinuierlicher Investitionen in die Datenqualität für den Erfolg in der modernen, datengetriebenen Wirtschaft bietet das E-Book "Datenqualität in KI-Projekten" eine Fülle an wertvollen Einblicken und praktischen Lösungsansätzen.
